
Sometimes it seems like you have to travel far in order to meet your neighbours. I had that experience recently went I went to the STC conference in Washington, D.C., and got reacquainted with “Single Sourceror” Rob Hanna of Precision Content, who lives in the same city that I do (Toronto). While I’ve known Rob for a while—mainly by running into him at the occasional conference—I thought it was time to ask him about how he got started in technical writing, his ideas on DITA and Information Mapping® and on the support he has given for the upcoming Lightweight DITA standard.
DITAWriter: How did you get started in technical writing and when did you first encounter DITA?
Rob Hanna: My first real stint as a technical writer was in 1997 at CAE Ltd. in Mirabel, QC. I was a lone technical writer hired to support almost 100 engineers who were responsible for the onboard systems and flight simulator software for Canada’s fleet of F-18 fighter aircraft. I didn’t know it at the time but I was going far into the deep end of technical communication working with GML markup, Oracle databases, taxonomies, configuration management systems, and complex publishing systems.
At CAE the engineers truly valued the importance of precise software documentation. They created and maintained highly structured topics to describe the software requirements and design elements. These topics followed the software components through an Agile-like software development lifecycle. If the topics did not meet the required quality standards, the accompanying software bundle was held back until the documentation was corrected.
I could not have received a better education in content development anywhere else. Of course, I was shocked and dismayed to learn afterwards that the rest of the technical communication field did not work quite the same way. My entire career has been dedicated to finding my way back to this Valhalla of technical communication.
A few years later, I was working as an information architect for a large Canadian retailer. My task was to create an information metamodel to use to classify a large collection of software documentation. This model identified generic information types that could be used to classify small components of content based upon the state of the information at any point in the product development lifecycle. I was able to apply a lot of what I had learned at CAE to come up with my model.
Research into my modelling efforts eventually lead me to DITA and Information Mapping®. In 2003, I published my first conference paper for the STC on the information management model. I’ve been working with DITA on one level or another ever since.
DITAWriter: Tell me about Information Mapping® and how you think it can be used by DITA practitioners
Rob Hanna: Robert Horn’s compilation of research into learning theory and human cognition in the 1960’s led to the formation of the Information Mapping® methodology that is taught by Information Mapping International. While Information Mapping is not cited directly as the source for DITA’s information types, there is a strong correlation with a subset of types defined in the methodology. The following table helps make this clear:
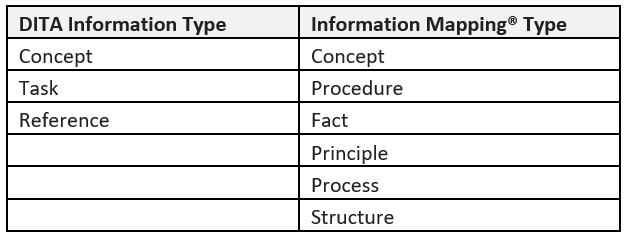
While information typing is only a part of the methodology, it can be highly instructive for DITA authors looking to understand what information types are and how they can be better differentiated within technical communication. This clarity and the broader set of information types allows for better application of the semantics in DITA, making the DITA content they create more consistent.
The other aspect of Information Mapping® that is missing from DITA is the notion of typing not just at the topic level but also at the block or section level as well. This lower level of semantic granularity provides for greater precision in how DITA content can be written.
DITAWriter: Tell me how you’ve brought these two elements together.
Rob Hanna: In 2008, I was working with the Enterprise Business Document Subcommittee studying how we could extend DITA beyond technical publications. My task was to research existing models that could be used to help build new semantics for the enterprise. I approached Information Mapping Canada at the time to bring them into the conversation about enterprise documentation. Thus began a journey for me to find ways to bring the DITA framework together with the Information Mapping® methodologies.
In 2012, Information Mapping Canada found a customer looking to bring together Information Mapping with DITA technology. I was brought on to consult on applying DITA technology to the methods. Soon after, I developed the Precision Content® solution that adapts several of the methods taught by Information Mapping international and specializes many of the structures used in DITA. Today, I have a thriving business helping companies across North America move to structured authoring using our Precision Content® approach.
DITAWriter: Could you provide a more concrete example of how Information Mapping® can be applied to DITA content to provide more granular levels of reuse?
Rob Hanna: By focusing on how we write blocks used in topics, we can narrow the scope of a block to a specific intended user response.
For example, consider the following two phrases: “the reader needs to understand what an SSRI inhibitor is so that he or she can differentiate this class of drug from other similar classes” or “the reader needs to be advised not to power off their PC before the software update has completed as this may cause the reader’s PC to become unstable”. Each of these intended user responses corresponds to a specific information type that is assigned as an attribute on the block by the author. For each type of information we can apply specific rules for how the content is labelled, written, and presented to the reader. This level of precision allows for better opportunities for reuse of these blocks across other topics. These blocks are easily findable and unambiguous as to their intent.
DITAWriter: I know that Precision Content has a real interest in Lightweight DITA and that one of your people (Tim Grantham) is a key technical member of that group. What do you see as possible future uses for Lightweight DITA?
Rob Hanna: Lightweight DITA is intended to make structured authoring available to the masses to allow for any knowledge worker to contribute to a corpus of content. A refined architecture that aligns with the more complex version of the standard will lead to the creation of new tools and user interfaces that will in turn lead to greater uptake across the enterprise.
We teach our Precision Content® methods on any tool and format. With Lightweight DITA, we’ll have a better platform for a more custom-built Precision Content® authoring environment. I expect that we will still rely on the XML variant for its structural validation over HTML (HDITA) and markdown (MDITA).
While some see Lightweight DITA as a potential stepping-stone for groups to ease their way into full DITA authoring, I believe that the best value will be realized by groups that use Lightweight DITA to supplement a full DITA deployment. In these cases, there will be contributors that will never need to move over to full DITA authoring.
Note on the registered trademarks: when either the Information Mapping® or Precision Content® methodologies are mentioned and not as part of a company name, I have been asked to add the registered trademark symbol. When referring to either company in the short, informal version of their respective names, the symbol is not required. I mention this only because this blog is aimed at technical writers and we are famously nit-picky when it comes to things like this. 😉
Generally speaking, the trademark marks only need to be shown on the first instance of that trademark appearing in a text.
Agreed, but in this case I am following the instructions I was given. This is why I included the note at the end, and better to be safe than sorry.